
El SEO técnico es la base que permite que motores de búsqueda, sistemas de IA y usuarios humanos descubran, rendericen y entiendan un sitio web. Cuando esa base se rompe, la calidad del contenido y el pulido visual no pueden sostener al negocio.
Para negocios de servicios, contratistas, consultores y startups, los errores de SEO técnico no son problemas abstractos de ranking. Bloquean que prospectos cualificados encuentren servicios, ralentizan formularios de leads, confunden a los motores de búsqueda sobre páginas canónicas y debilitan workflows automatizados de ventas.
Esta guía explica los errores comunes de SEO técnico que dañan la visibilidad en búsqueda, la indexación con IA y el rendimiento de conversión. También muestra cómo diagnosticar los problemas, priorizar la remediación y construir una arquitectura de sitio que soporte SEO moderno, Core Web Vitals, schema, Generative Engine Optimization, Answer Engine Optimization y automatización de leads.
La realidad de negocio de las deficiencias de SEO técnico
Un sitio web de negocio de servicios debe funcionar como un sistema de generación de leads. Los errores de SEO técnico crean fricción dentro de ese sistema.
Si los motores de búsqueda no pueden rastrear el sitio web con eficiencia, el negocio se vuelve invisible para compradores que están buscando activamente sus servicios. Si las etiquetas canonical apuntan a páginas obsoletas, los motores de búsqueda pueden indexar contenido de servicio irrelevante o información de contacto antigua. Si una página tiene Interaction to Next Paint deficiente, un prospecto que intenta abrir un menú, usar una calculadora de precios, enviar un formulario o interactuar con un chatbot puede abandonar la sesión antes de convertir.
En un entorno de búsqueda con IA, el costo es aún mayor. Los sistemas de respuesta con IA y los navegadores agentic dependen de estructura limpia, layouts estables, contenido accesible e indexación fiable. La deuda técnica puede excluir al negocio de resultados de búsqueda tradicionales y de respuestas generadas.
Por qué la mayoría de negocios lo hacen mal
Muchos negocios tratan el sitio web primero como un asset visual y segundo como un sistema técnico. Esa prioridad suele crear templates pesados en JavaScript, medios sobredimensionados, plugins frágiles, URLs duplicadas y HTML thin que se ve aceptable para una persona pero crea ambigüedad para crawlers.
El SEO técnico también se trata demasiado a menudo como un checklist de lanzamiento en lugar de una disciplina operativa. Actualizaciones de CMS, cambios de plugins, migraciones, eliminaciones de páginas, nuevas páginas de ubicación, parámetros de tracking y cambios de diseño pueden introducir problemas de crawl e indexación después del lanzamiento.
Ejemplos comunes incluyen:
- Una directiva
noindexde staging que llega accidentalmente a producción. - Una regla
robots.txtque bloquea páginas importantes o assets de renderizado. - Páginas de servicio eliminadas sin redirección 301.
- Cadenas de redirección que ralentizan crawlers y usuarios.
- Title tags duplicados, contenido duplicado y etiquetas canonical conflictivas.
- Contenido solo en JavaScript que crawlers y sistemas de IA no pueden parsear con fiabilidad.
El fallo normalmente viene de una desconexión entre diseño, desarrollo, marketing y mantenimiento técnico continuo.
Metodologías de diagnóstico y protocolos de triage
El diagnóstico de SEO técnico debe empezar con evidencia, no con revisión subjetiva de páginas. La primera fuente de verdad es Google Search Console porque reporta cómo Google ve la rastreabilidad, indexación, acciones manuales, problemas de sitemap y datos de campo de Core Web Vitals.
Search Console no basta por sí solo. Principalmente reporta URLs que Google ya conoce. Para descubrir problemas de arquitectura de forma proactiva, usa herramientas de crawling como Screaming Frog, Ahrefs, Lumar, Sitebulb o Semrush. Estas herramientas simulan comportamiento de crawler, mapean enlaces internos, identifican páginas huérfanas, exponen enlaces rotos y muestran cadenas de redirección.
| Categoría de herramienta diagnóstica | Función central | Problemas identificados |
|---|---|---|
| Consolas de motores de búsqueda | Feedback directo del motor e indexación | Errores de crawl, acciones manuales, indexación de staging, datos de campo de Core Web Vitals |
| Crawlers de emulación | Mapeo de arquitectura y análisis de enlaces internos | Enlaces rotos, páginas huérfanas, loops de redirección, metadata faltante, títulos duplicados |
| Analizadores de logs | Revisión de logs del servidor sobre comportamiento de bots | Crawl budget desperdiciado, rutas infinitas de crawl, recursos bloqueados, recorrido real de crawlers |
| Testing de datos estructurados | Validación JSON-LD | Errores de sintaxis schema, propiedades obligatorias faltantes, schema boilerplate, markup no coincidente |
Qué arreglar primero
La primera prioridad siempre es acceso de crawl e indexación. Si una landing page primaria está bloqueada por robots.txt o tiene una directiva noindex, el trabajo de rendimiento, reescritura de contenido y link building no resolverá el problema de visibilidad.
Después de restaurar acceso, avanza por la jerarquía:
- Eliminar barreras de crawl e indexación.
- Arreglar enlaces internos rotos, 404s, loops de redirección y cadenas de redirección.
- Resolver URLs duplicadas, conflictos canonical y contaminación del sitemap.
- Mejorar Core Web Vitals, especialmente LCP, INP y CLS.
- Validar schema y fortalecer claridad de entidad.
- Mejorar legibilidad para búsqueda con IA mediante contenido único, estructurado y experto.

Este triage evita que los fallos de mayor impacto queden enterrados bajo pulido de menor prioridad.
Indexación, rastreabilidad y directivas
Los errores de SEO técnico más dañinos suelen ocurrir en la capa de directivas.
Un archivo robots.txt mal configurado frecuentemente empieza en desarrollo. Los equipos bloquean crawlers en entornos de staging y luego despliegan accidentalmente la misma directiva a producción. Si Disallow: / llega al sitio live, los motores de búsqueda pueden recibir la instrucción de no rastrear todo el dominio.
El error opuesto también es común: entornos de staging se dejan accesibles públicamente. Si un subdominio de desarrollo puede rastrearse e indexarse, el sitio de producción puede competir contra su propio clon inacabado.
Los XML sitemaps necesitan la misma disciplina. Un sitemap debe incluir solo URLs canónicas e indexables. No debe incluir redirecciones, páginas eliminadas, URLs noindex, URLs duplicadas con parámetros ni páginas utilitarias de bajo valor. Los sitios dinámicos deben generar sitemaps automáticamente cuando se añaden o eliminan páginas de servicio, páginas de ubicación y artículos.

Fallos de duplicación y canonical
El contenido duplicado crea ambigüedad. Cuando el mismo contenido o contenido casi idéntico aparece en varias URLs, los motores de búsqueda deben decidir qué versión debe llevar autoridad.
La duplicación suele venir de:
- URLs parametrizadas como
?source=newsletter. - Navegación facetada.
- Variantes HTTP y HTTPS resolviendo por separado.
- Variantes
wwwy non-wwwresolviendo por separado. - Archivos CMS o páginas de etiquetas que duplican contenido primario.
- Páginas de servicio o ubicación casi idénticas.
La etiqueta canonical indica a los motores de búsqueda qué URL es la versión preferida. Pero los canonicals incorrectos pueden empeorar el problema. Evita etiquetas canonical que apunten a 404s, URLs que redirigen, páginas no relacionadas o versiones parametrizadas que no deberían indexarse.
Enlaces rotos y cadenas de redirección
Los enlaces internos distribuyen autoridad y ayudan a los motores de búsqueda a entender clusters temáticos. Los enlaces internos rotos crean callejones sin salida. Desperdician rutas de crawl y dañan la confianza del usuario.
Las redirecciones son útiles cuando el contenido se mueve, pero deben ser directas. Una URL legacy debe redirigir al destino final en un solo salto. Cadenas como URL A a URL B a URL C añaden latencia, desperdician crawl budget y eventualmente pueden ser abandonadas por crawlers.
Para migraciones, mantén un mapa de URLs. Cada URL legacy importante debe tener un destino claro antes del lanzamiento.
Consideraciones de desarrollo web y rendimiento
El SEO técnico ahora incluye rendimiento real de usuario. Los Core Web Vitals de Google miden si las páginas cargan rápido, responden a la interacción y se mantienen visualmente estables.
Las métricas principales son:
| Métrica | Objetivo saludable | Qué revela |
|---|---|---|
| Largest Contentful Paint | 2.5 segundos o menos | Si el contenido visible principal carga rápido |
| Interaction to Next Paint | 200 milisegundos o menos | Si la página responde rápido al input del usuario |
| Cumulative Layout Shift | 0.1 o menos | Si la página permanece visualmente estable |
Core Web Vitals y el reinado de INP
Interaction to Next Paint reemplazó First Input Delay como métrica clave de responsividad porque mide interacciones durante toda la sesión, no solo el primer input. INP captura el tiempo desde la entrada del usuario hasta que se pinta el siguiente frame visual.
Un INP deficiente normalmente es un problema de JavaScript. Si el main thread del navegador está ocupado ejecutando un script grande, no puede responder rápido a clics, taps, input de teclado, menús, campos de formulario, acordeones o widgets de chat.
Correcciones comunes de INP incluyen:
- Dividir grandes bundles de JavaScript en chunks más pequeños.
- Diferir scripts no críticos.
- Ceder el main thread durante trabajo costoso.
- Mover cómputo pesado no DOM a Web Workers.
- Reducir tamaño de DOM y recálculos de layout costosos.
- Eliminar o reemplazar scripts de terceros inflados.
LCP y estabilidad visual
Largest Contentful Paint mide qué tan rápido aparece el contenido visible principal. En sitios de negocios de servicios, el elemento LCP suele ser la hero image, el bloque de headline o medios above-the-fold.
Mejora LCP comprimiendo imágenes, usando formatos modernos, precargando assets prioritarios, reduciendo tiempo de respuesta del servidor, eliminando recursos que bloquean renderizado y manteniendo liviano el diseño above-the-fold.
Cumulative Layout Shift mide si la página se mueve inesperadamente. El layout shift suele venir de imágenes sin dimensiones, embeds sin espacio reservado, banners inyectados por encima del contenido o cambios de fuentes que modifican dimensiones de texto.
Define dimensiones de medios, reserva espacio para componentes dinámicos y evita insertar nuevos elementos above-the-fold después de que el layout inicial ha cargado.
Client-Side Rendering vs Server-Side Rendering
Los frameworks JavaScript pueden crear problemas SEO cuando dependen de client-side rendering por defecto. Con client-side rendering, el servidor puede enviar un shell HTML thin y un gran bundle JavaScript. Los crawlers entonces necesitan descargar, parsear y ejecutar JavaScript antes de poder ver el contenido.
Los motores de búsqueda pueden renderizar JavaScript, pero el renderizado cuesta tiempo y recursos. Algunos crawlers y sistemas de IA no lo renderizan de forma fiable. Contenido crítico, navegación, metadata, canonical tags, enlaces internos, schema, descripciones de servicio y detalles de ubicación no deben depender de ejecución client-side frágil.
Usa server-side rendering, generación estática o renderizado híbrido para páginas que deben rankear y convertir.
Schema markup y reconocimiento de entidades
Schema markup traduce el contenido de página en datos estructurados legibles por máquinas. JSON-LD ayuda a motores de búsqueda a identificar entidades, relaciones, tipos de página, servicios, detalles de negocio local, artículos, FAQs, breadcrumbs y reseñas.
Un buen schema puede apoyar rich results y un entendimiento de entidad más claro. Un mal schema puede eliminar elegibilidad para rich results o crear problemas de calidad.
Schema boilerplate y engañoso
Un error común es el schema boilerplate. Ocurre cuando el mismo JSON-LD genérico se inyecta en cada página. Una página de servicio, artículo, página de ubicación y portfolio item no deben presentar todos los mismos datos estructurados a nivel de página.
Un problema más serio es el schema que contradice la página visible. Los datos estructurados deben describir contenido que los usuarios realmente pueden ver. No marques FAQs ocultas, reseñas fabricadas, ofertas invisibles o tipos de página que no coinciden con el cuerpo del contenido.
Los motores de búsqueda tratan los datos estructurados engañosos como problema de calidad porque intentan ganar rich results sin contenido visible de apoyo.
Sintaxis y propiedades obligatorias
JSON-LD debe ser válido. Una coma faltante, una coma final, una comilla sin cerrar o un array mal formado puede invalidar el script.
Los tipos de schema también requieren las propiedades correctas:
FAQPagedebe contener preguntas y respuestas aceptadas que coincidan con contenido FAQ visible.Productrequiere detalles del producto y datos válidos de oferta, reseña o aggregate rating cuando se usan esas funciones.LocalBusinessrequiere identidad precisa del negocio, dirección, contacto y detalles de ubicación cuando corresponda.ArticleoBlogPostingdebe describir headline del artículo, autor, fechas, publisher, imagen y URL de página.
Los negocios de servicios deben usar schema específico cuando sea posible. Un nodo genérico Organization es útil, pero no debe reemplazar markup específico de página para servicio, artículo, negocio local, breadcrumb o FAQ.
GEO, AEO y optimización para búsqueda con IA
Generative Engine Optimization y Answer Engine Optimization son extensiones de SEO técnico, no reemplazos.
AI Overviews, AI Mode, ChatGPT Search, Perplexity, Gemini, Copilot y sistemas similares recuperan información, la resumen y citan un conjunto más pequeño de fuentes. Los mismos problemas técnicos que bloquean la búsqueda tradicional también pueden bloquear visibilidad con IA.
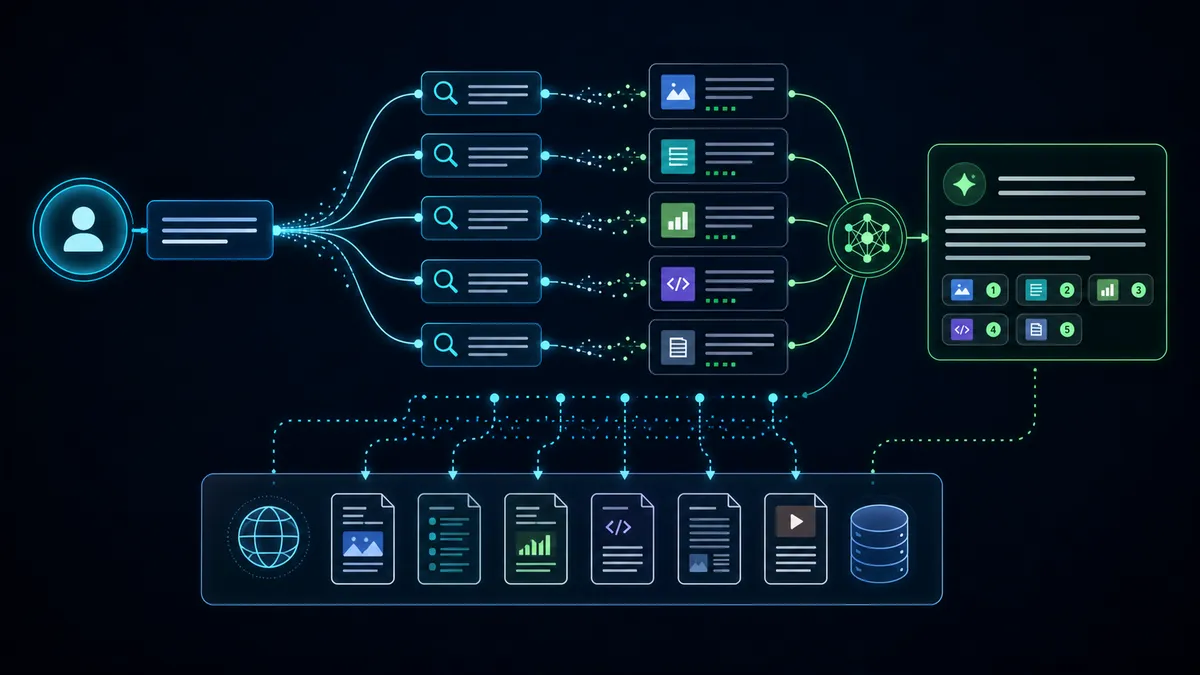
RAG, query fan-out y mecánicas de IA
Retrieval-Augmented Generation significa que el sistema de IA recupera información actual desde un índice o fuentes externas antes de sintetizar una respuesta. Query fan-out significa que un prompt complejo puede dividirse en muchas búsquedas más pequeñas.
Por ejemplo, una pregunta sobre requisitos de instalación HVAC comercial puede convertirse en búsquedas separadas sobre códigos locales, dimensionamiento de equipos, eficiencia energética, proveedores de servicio, permisos y variables de costo.
Si el sitio web del negocio está bloqueado, lento, duplicado, thin, dependiente de JavaScript o semánticamente poco claro, es un candidato débil para retrieval.
Desmontando mitos de optimización para IA
La optimización para IA suele venderse como un conjunto de atajos. La mayoría de atajos distraen de la base técnica.
Evita:
- Crear archivos específicos para IA mientras ignoras rastreabilidad, indexación, calidad de contenido y schema.
- Romper contenido long-form fuerte en fragmentos thin por asumir que la IA no puede procesar matices.
- Meter permutaciones de keywords en el copy en lugar de escribir respuestas claras, expertas y respaldadas por fuentes.
- Tratar la búsqueda con IA como separada del índice web estándar.
Para ganar citaciones de IA, publica contenido útil, técnicamente accesible y no commodity. Los sistemas de IA pueden resumir consejos genéricos. Es más probable que citen fuentes que ofrecen expertise original, frameworks específicos, claridad fuerte de entidad y estructura fiable de página.
Estructura de sitio amigable para agentes
Los agentes de IA y sistemas de automatización de navegador necesitan estructura semántica. Interpretan el DOM, layout visible, formularios, botones, labels y estados interactivos.
Una página agent-friendly debe usar:
- Elementos
<a>reales para enlaces. - Elementos
<button>reales para acciones. - Labels de formulario claros conectados a inputs.
- Layouts estables sin overlays inesperados.
- Nombres accesibles para controles.
- Rutas de conversión visibles.
Esto no es solo una cuestión de accesibilidad. Afecta si sistemas automatizados pueden entender y completar tareas en la página.
Oportunidades de conversión y automatización con IA
El SEO técnico es la base del diseño web orientado a conversión. Una página puede rankear bien y aun así desperdiciar tráfico si la experiencia de usuario bloquea la captura de leads.
Core Web Vitals afectan la conversión directamente. Un CLS alto puede causar misclicks. Un INP deficiente puede hacer que herramientas de pricing y formularios se sientan rotos. Un LCP lento puede hacer que usuarios abandonen antes de ver la oferta.
Schema y claridad semántica también apoyan conversión. Resultados de búsqueda con detalles de negocio, servicios, reseñas, FAQs y breadcrumbs precisos pueden atraer visitantes más cualificados antes de que lleguen al sitio.
Workflows de leads
Una vez que la base técnica es fiable, los negocios de servicios pueden conectar tráfico SEO con automatización con IA:
- Asistentes de IA pueden responder preguntas de servicio usando contenido aprobado del sitio y datos CRM.
- Flujos de cualificación de leads pueden puntuar prospectos por presupuesto, timeline, necesidad de servicio y ubicación.
- Integraciones CRM pueden enrutar leads de alto valor hacia follow-up prioritario.
- Automatización de email y SMS puede reducir retrasos de speed-to-lead.
Estos workflows requieren un sitio técnicamente estable. Si los formularios son inaccesibles, APIs son frágiles, scripts son lentos o la estructura de página no es clara, la automatización crea más puntos de fallo en lugar de más ingresos.
Enfoque estratégico para negocios de servicios
Los negocios de servicios necesitan una arquitectura holística que conecte SEO, desarrollo, localización, schema y conversión.
Empieza eliminando deuda técnica. Rastrea el sitio, repara enlaces rotos, colapsa cadenas de redirección, limpia directivas robots, valida sitemaps y confirma URLs canónicas.
Luego fortalece la base local y móvil. Los negocios locales de servicios necesitan señales de ubicación precisas, layouts mobile-first, respuesta rápida a taps, formularios accesibles y schema que refleje áreas reales de servicio.
Estructura recomendada de enlaces internos
Una estructura fuerte de enlaces internos debe hacer que el negocio sea fácil de entender:
- La homepage enlaza a servicios principales, ubicaciones, insights, about, contact y rutas de booking.
- Las páginas hub de servicio enlazan a ofertas específicas de servicio y artículos relevantes.
- Las páginas de ubicación enlazan a los servicios disponibles en ese mercado.
- Los artículos enlazan de vuelta a páginas de servicio donde el lector puede actuar.
- Las rutas de contacto y booking están disponibles desde cada journey comercial.
Los enlaces internos deben usar anchor text descriptivo y anchors HTML reales para que crawlers y usuarios puedan seguirlos.
Errores críticos a evitar
No despliegues librerías JavaScript masivas sin controles de rendimiento. Un INP alto daña rankings y conversión.
No uses schema para marcar contenido oculto, reseñas falsas, datos de producto no relacionados o boilerplate genérico en cada página.
No dejes que controles de staging lleguen a producción. Audita robots.txt, noindex, canonical tags y autenticación antes de cada lanzamiento.
No persigas gimmicks de IA mientras ignoras indexación, velocidad, claridad de entidad y expertise única.
Checklist práctico
- Rastreabilidad: audita
robots.txtpara bloqueos accidentales y confirma que assets importantes puedan cargar. - Indexación: revisa etiquetas
noindexsobrantes en páginas comerciales y protege entornos de staging con autenticación. - Arquitectura: rastrea el sitio para encontrar enlaces rotos, páginas huérfanas, cadenas de redirección y metadata duplicada.
- Canonicalización: confirma que cada URL importante tenga un canonical válido que coincida con redirecciones, sitemaps y enlaces internos.
- Rendimiento: audita INP, LCP y CLS usando datos de campo cuando estén disponibles.
- Renderizado: confirma que contenido crítico, navegación, metadata, enlaces y schema estén disponibles sin comportamiento client-side frágil.
- Schema: valida JSON-LD y asegura que coincida con el contenido visible de la página.
- Preparación para agentes: usa HTML semántico, labels accesibles, layouts estables y rutas claras de conversión.
Recomendación final
El SEO técnico es ingeniería estructural para la visibilidad digital moderna. Motores de búsqueda, sistemas de IA y usuarios tienen poca tolerancia para páginas inaccesibles, interacciones lentas, URLs duplicadas, enlaces rotos, schema engañoso o renderizado JavaScript frágil.
Los negocios de servicios no deben depender solo del diseño visual. Un sitio web debe ser rápido, rastreable, indexable, semánticamente explícito, listo para móvil y conectado a workflows de leads. Arreglar la base técnica es el primer paso hacia visibilidad sostenible en búsqueda, descubrimiento con IA y crecimiento de conversión.